|
I am currently working as an Applied Scientist with the Contextual Ads team at Amazon where I leverage large language models (LLMs) towards improving Contextual Advertising products at Amazon. Previously, I've also worked as an Applied Scientist with the Search Science and AI team at Amazon where I worked on training LLMs towards building universal state-of-the-art semantic representations of Amazon-specific entities. I completed my Master's in Computational Data Science at Carnegie Mellon University, PA in December 2020. During my Master's, I interned as an Applied Scientist intern at Amazon Search in summer 2020 where I developed deep learning models to link context-of-use entities with products to improve search experience of products. Prior to that, I've worked as a Research Intern at the Visual Learning and Intelligence (VIGIL) Lab at Indian Institute of Technology, Hyderabad, India under Dr. Vineeth Balasubramanian. to develop a novel multi-space approach to Zero-Shot Object Detection. This work has been accepted at WACV 2020! I obtained my Bachelor's degree in Information Technology from National Institute of Technology Karnataka, Surathkal, India. During my Bachelor's, I interned at Microsoft (R&D), Hyderabad, India with the Azure Networking Team in the summer of 2018. My interests are broadly in machine learning, natural language processing and computer vision. I have worked on problems in the domains of click-through rate prediction, product retrieval, knowledge distillation, spell correction, object detection, fact verification, visual question answering and paraphrase detection. Email / Resume / Google Scholar / Github / LinkedIn |

|
|
|
|
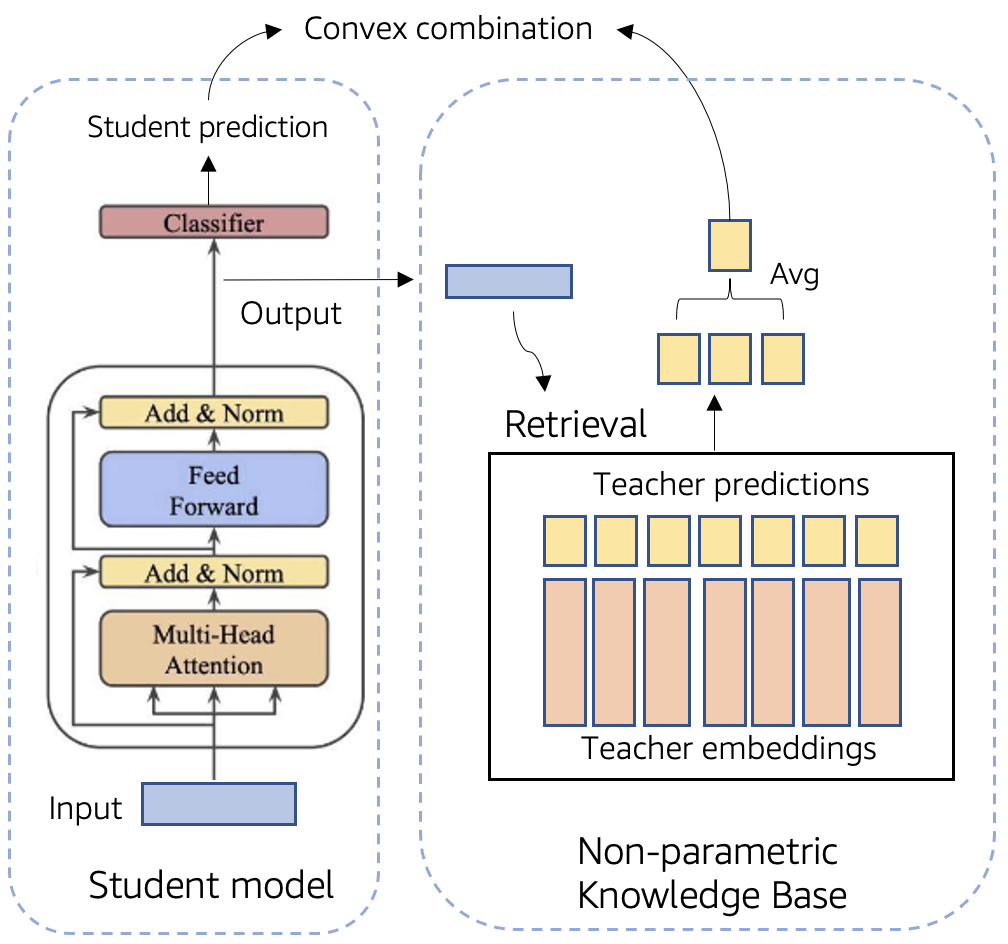
ReAugKD: Retrieval-Augmented Knowledge Distillation For Pre-trained Language Models
Jianyi Zhang, Aashiq Muhamed, Aditya Anantharaman, Guoyin Wang, Changyou Chen, Kai Zhong, Qingjun Cui, Yi Xu, Belinda Zeng, Trishul Chilimbi, Yiran Chen Association for Computational Linguistics (ACL 2023) (Oral), Toronto, Canada [Paper] [Blog] Developed a knowledge distillation framework called ReAugKD that leverages retrieval-augmented distillation from a non-parametric knowledge base of teacher model's soft labels and embeddings which shows state-of-the-art performance on the GLUE benchmark. |
|
Graph Relation Transformer: Incorporating pairwise object features into the Transformer architecture
Michael Yang*, Aditya Anantharaman*, Zachary Kitowski*, Derik Clive Robert* Visual QA Workshop, Conference on Computer Vision and Pattern Recognition (CVPR 2021) [Paper] Proposed a multimodal Graph Relation Transformer which leverages transformer layers for graph attention computation with rich edge and node information for the Text-VQA task. |
|
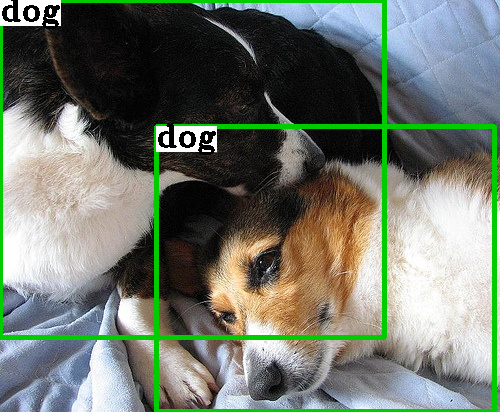
A Multi-Space Approach to Zero-Shot Object Detection
Dikshant Gupta, Aditya Anantharaman, Nehal Mamgain, Sowmya Kamath, Vineeth Balasubramanian, C V Jawahar Winter Conference on Applications of Computer Vision (WACV 2020), Colorado, USA [Paper] Developed a novel Multi-Space model for Zero-Shot Object Detection (ZSD). Leveraged both semantic and visual spaces and introduced a cross-modal consistency loss to alleviate hubness. Outperformed the state-of-the-art in ZSD on Pascal VOC by 14% in terms of mAP. |
|
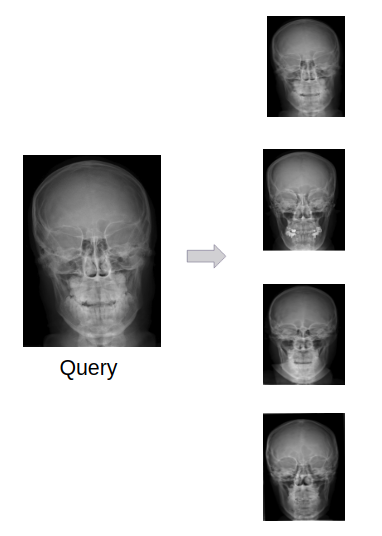
Mandikal Vikram, Aditya Anantharaman, Suhas B S, Sowmya Kamath The ACM India Joint International Conference on Data Science & Management of Data (CoDS-COMAD), Kolkata, India 2019 (Oral Presentation) [Paper] [Code] A short version was accepted at the AI for Social Good Workshop, NeurIPS, Montreal, 2018 [Paper] [Poster] Latent Dirichlet Allocation (LDA) based technique for encoding the visual features of the medical images along with novel early fusion and late fusion techniques to combine the textual and visual features. |
|
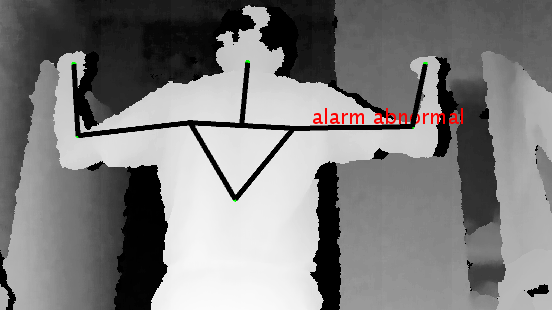
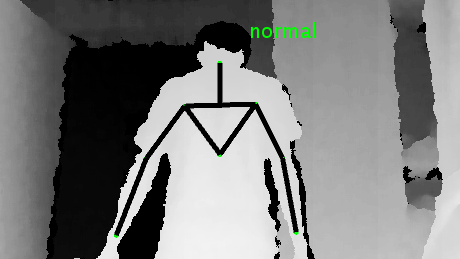
Mandikal Vikram, Aditya Anantharaman, Suhas B S, Ashwin TS, Ram Mohana Reddy IEEE Indicon, Coimbatore, India 2018 [Paper] [Poster] Using the Microsoft Kinect depth camera to detect suspicious postures and build a real-time home security system which is robust towards changing lighting conditions. |
|
|